 Michele Bursi
Michele Bursi Ahmad Tolba
Ahmad Tolba Dat Tang
Dat Tang Jenny Kim
Jenny Kim Mawreen Dela Cruz
Mawreen Dela Cruz Mayra Cabrera
Mayra Cabrera Dave Smith
Dave Smith Alessio Caiazza
Alessio Caiazza Anthony Maina Ng'ang'a
Anthony Maina Ng'ang'a John T Skarbek
John T Skarbek Reuben Pereira
Reuben Pereira Vladimir Glafirov
Vladimir Glafirov Ameya Darshan
Ameya Darshan André Luís
André Luís Steve Abrams
Steve AbramsDelivery Team Metrics
The Delivery Team enables GitLab Engineering to deliver features in a safe, scalable and efficient fashion to both GitLab.com and self-managed customers.
| Workflow | Team workflow |
| GitLab.com | @gitlab-org/delivery |
| Issue Tracker | Delivery |
| Slack Channels | #g_delivery / @delivery-team |
| Delivery Handbook | Team training |
| Delivery Metrics | Metrics |
| Deployment and Release process | Deployments and Releases |
| Release Tools Project | Release tools |
| Release Manager Runbooks | release/docs/runbooks |
The Delivery Group enables GitLab Engineering to deliver features in a safe, scalable and efficient fashion to both GitLab.com and self-managed customers. The group ensures that GitLab’s monthly, security, and patch releases are deployed to GitLab.com and publicly released in a timely fashion.
The Delivery Group is a behind the scenes, primarily internal user facing team whose product and output has a direct impact on Infrastructure’s primary goals of availability, reliability, performance, and scalability of all of GitLab’s user-facing services as well as self-managed customers. The group creates the workflows, frameworks, architecture and automation for Engineering teams to see their work reach production effectively and efficiently.
The Delivery Group is focused on building a fully-automated deployment and release platform that builds on the CI/CD blueprint to enable fast, flexible releases and deployments with rapid rollout, failure detection and recovery.
Each member of the Delivery group is part of this vision:
These are a set of statements or questions we can use within the group to evaluate whether what we are doing is the right thing to do. When deciding on a piece of work to commit to, we should ask ourselves whether the work aligns with these principles. The principles will be driven by the Delivery Group Strategy, domain experts and Delivery Group Members. These are likely to change slightly over time as we learn and should not be considered static. Additionally, these principles are additive to the GitLab Values and we aim not to duplicate those here.
These principles are intended to help everyone work independently in a way that is aligned with our Group and strategy.
We’ve moved this subsection to the Delivery direction pages so that it’s in the same place as the rest of our product direction.
The group regularly works on the following tasks, in the order of priority:
The Delivery Group is composed of two teams: Delivery:Releases and Delivery:Deployments.
The Delivery:Releases and Delivery:Deployments OKRs, while contributing to the wider GitLab objectives, are tailored and structured to achieve the Delivery Group Strategy as a single team.
The primary goal of the Releases team is to provide everything to do with creating GitLab releases for customers and enabling internal customers to get their changes into releases. Major, minor and patch releases as well as a platform on which we can verify changes to various installation types (release environments) and create visibility for GitLab team members and customers into our release schedule (release dashboard).
The primary goal of the Deployments team is to provide everything to do with rolling out changes to active platforms managed by GitLab, including but not limited to continuous deployment to GitLab.com (deployment safety), changing gitlab.com architecture to support continuous deployment (eliminate staging 🤞 ) and thinking about how to optimise the rollout experience (zero downtime work).
The following people are members of the Delivery:Releases Team:
The following people are members of the Delivery:Deployments Team:
The following members of other functional teams are our stable counterparts:
Delivery Group contributes to Engineering function performance indicators through Infrastructure department performance indicators. The group’s main performance indicator is Mean Time To Production (MTTP), which serves to show how quickly a change introduced through a Merge Request is reaching production environment (GitLab.com). At the moment of writing, the target for this PI is defined in this key result epic.
MTTP is further broken down into charts and tables at the [Delivery Team Performance Indicators Sisense dashboard][Delivery Sisense PIs].
The Delivery Group owns the tools and capabilities needed for GitLab deployments and releases. The diagram below shows the split of domain ownership between the two teams and the current release managers. Where the domain overlaps with teams outside of the Delivery Group, we focus primarily on the deployments and releases capabilities and needs.
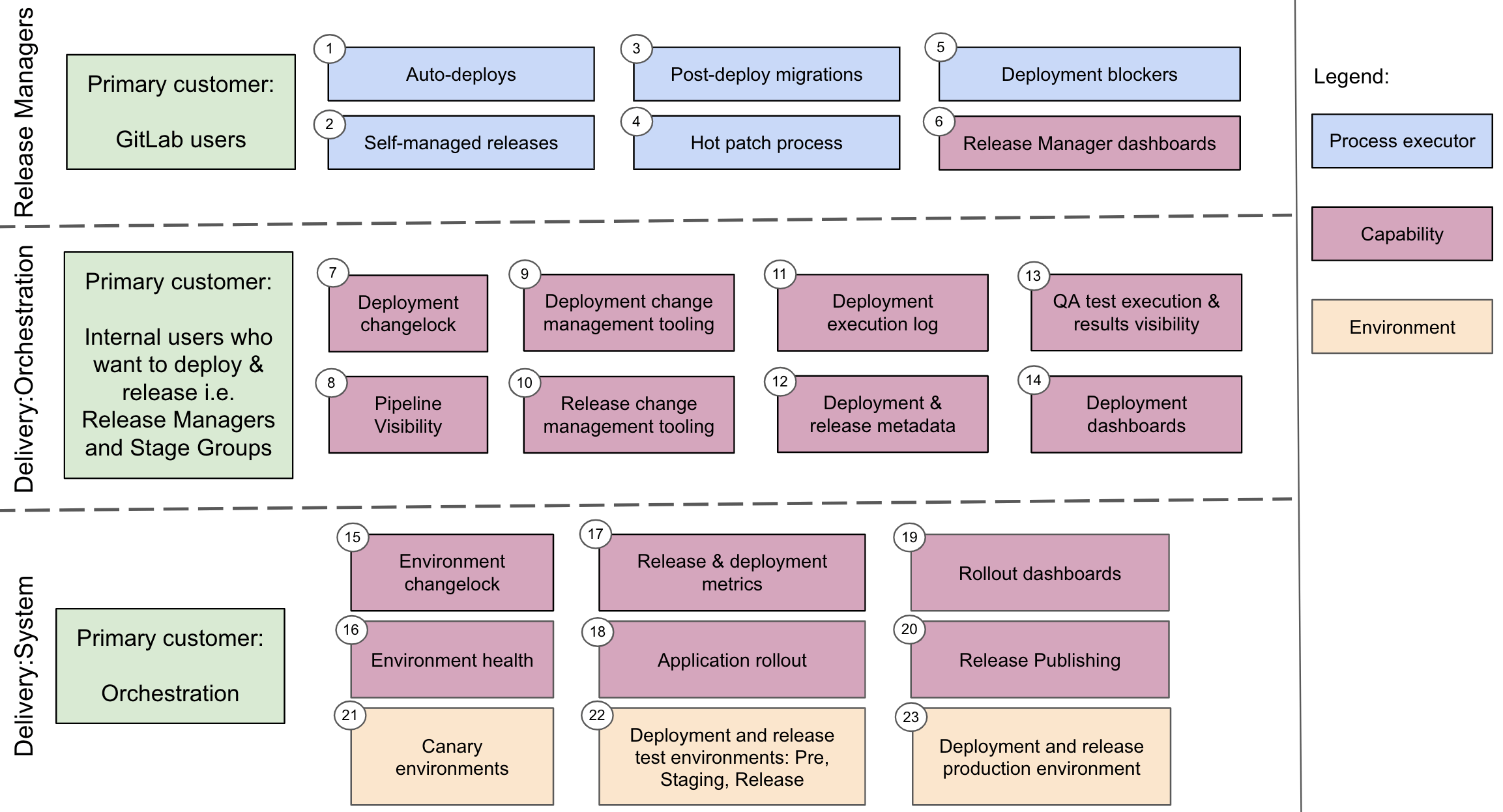
Release Managers are members of the Delivery group but during their time as release managers, they’re wearing a different hat. The primary customers are GitLab users.
The primary customers of the Releases team are:
The primary customers of the Deployments team are:
| Reason | Contact | Via |
|---|---|---|
| S1/P1 Deployment/Release related issues | @release-managers |
Slack |
| Any Priority Deployment/Release related issues | @gitlab-org/delivery |
GitLab |
Release Managers have a weekday follow-the-sun rotation and can be reached via the @release-managers handle on Slack. For weekend support or other escalations please use the Release Management Escalation steps below to reach Delivery Leaders.
During weekday working hours you can reach the current Release Manager via the @release-managers handle on Slack.
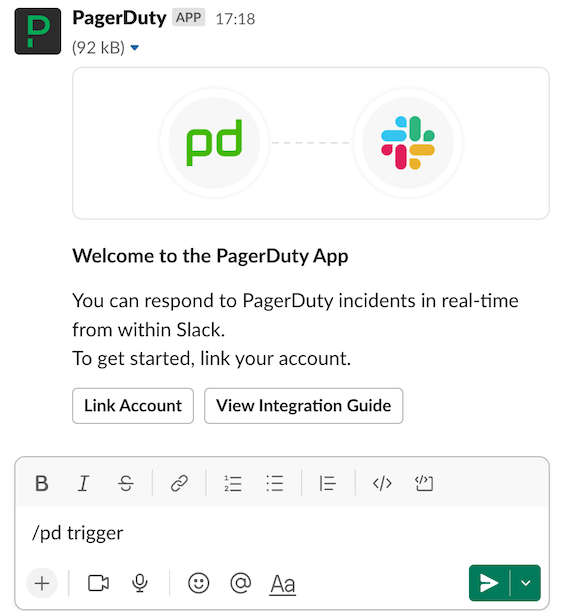
For release management support outside of working hours, or if you need to escalate to Delivery Leadership please follow the steps below to page using PagerDuty.
/pd trigger slack command to trigger a new incident
Release Management Escalation service and provide request details in the Title field. You can leave all other fields empty
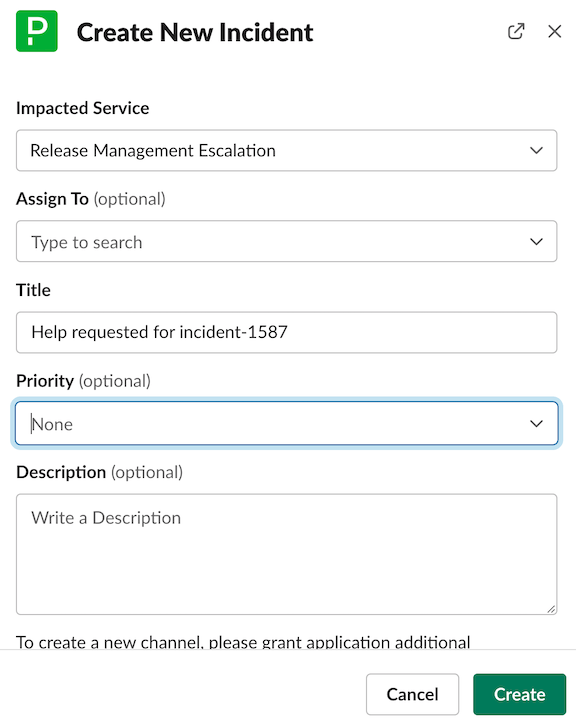
Create and one of the Delivery leaders will respondThe Delivery Group’s work is tracked through a number of epics, issues, and issue boards.
Epics and issue boards are complementary to each other, and we always strive to have a 1-1 mapping between a working epic and an issue board. Epics describe the work and allows for general discussions, while the issue board is there to describe order of progress in any given epic.
Each project should have a project-label applied to all epics and issues to allow issue boards to show a full project view.
Issues should primarily be created in the delivery issue tracker for visibility and prioritization. Repositories that Delivery maintain should have their own issue trackers disabled. The purpose of this is to ensure a single source of truth for work to be prioritized and visible within the team.
The Release Velocity epic tracks all work related to the group mission. Any working epic that the team creates should be directly added as a child to this top level tracking.
Working epic should always have:

kubernetes, security-release). The DRI should create a suitable project scope label and add it to the Delivery-triage rules if needed.In cases where the work is tracked in a project in a different group outside of our canonical project location, we will create two epics for the same topic and state in the epic description which one is the working epic.
Each working epic should be accompanied by an issue board. Issue boards should be tailored to the specific project needs, but at minimum it should contain the workflow labels shown on the workflow diagram.
The canonical issue tracker for the Delivery group is at gl-infra/delivery. Issues are automatically labeled if no labels are applied using the [triage ops] project. The default labels defined in the labeling library.
By default, an issue needs to have a:
workflow-infra::TriageDelivery::P4group::deliveryteam::Delivery-Deployments or team::Delivery-ReleasesThe Delivery group leverages scoped workflow-infra labels to track different stages of work.
Not every issue will be prioritised for building as soon as it is ready. Instead we manage a [Build board] with all workflow-infra::In Progress, and workflow-infra::Ready issues focused on the team’s current goals.
The standard progression of workflow is described below:
sequenceDiagram
participant ready as workflow-infra::Ready
participant progress as workflow-infra::In Progress
participant done as workflow-infra::Done
ready ->> progress: 1
Note right of ready: Issue is assigned and<br/> work has started.
progress ->> done: MR is merged and deployed to production
Note right of progress: Issue is updated with<br/>rollout details,<br/> workflow-infra::Done<br/> label is applied,<br/> issue can be closed.
There are three other workflow labels of importance omitted from the diagram above:
workflow-infra::Cancelled:
workflow-infra::Stalled
workflow-infra::Blocked
Label workflow-infra::Done is applied to signify completion of work, but its sole purpose is to ensure that issues are closed when the work is completed, ensuring issue hygiene.
The Delivery group uses priority labels to indicate order under which work is next to be picked up. Meaning attached to priorities can be seen below:
| Priority level | Definition |
|---|---|
| Delivery::P1 | Issue is blocking other team-members, or blocking other work. Needs to be addressed immediately, even if it means postponing current work. |
| Delivery::P2 | Issue has a large impact, contributes towards current OKRs or will create additional work. Work should start as soon as possible after completing ongoing task. |
| Delivery::P3 | Issue should be completed once other urgent work is done. |
| Delivery::P4 | Default priority. A nice-to-have improvement, non-blocking technical debt, or a discussion issue. Issue might be completed in future or work completely abandoned. |
The group uses priority labels differently to the general issue triage priority definition in order to avoid ambiguity that comes with difference in timelines between Stage teams and Infrastructure teams. We have different timelines (release brings different expectations for Delivery), different DRI’s (no PM for Delivery), and different importance (Blocked release means that no one can ship anything).
Some of the labels related to the team management are defined as:
onboarding - issues are related to granting access to team resources.team-tasks - issues related to general team topics.Discussion - meta issues that are likely to be promoted to a working epic or generate separate implementation issues.Announcements - issues used to announce important changes to wider audience.Project labels are defined as needed, but they are required unless the issue describes a team management task.
Incidents impacting Delivery may optionally include an impact label.
In addition to the Epics, Issue Boards, Labels, and Workflow practices common to the entire team, the Delivery:Deployments team adopts a few extra approaches to improve its communication and better share knowledge and decisions within the team.
Each Epic should contain a Decision Log: this helps to keep a single, centralized SSOT where all decisions taken during project work are listed. For completeness, we should report the date of the decision,
who was involved in the discussion and decision, and the outcome of the decision.
For simplicity, you can use the snippet below to add Decision Log to Epics Description:
|
|
Each Issue should contain a Progress Thread as a comment: this helps make the work visible in an async environment and shares knowledge while the work progresses.
Comments within the progress thread should highlight the progress achieved, the intermediate steps/results we got, assumptions, discoveries, and blockers we face.
This approach allows people from the team and outside of the team to build a clear idea and eventually contribute with comments and suggestions.
Each week, we should provide at least two status updates on Slack: Epics and Issues are our SSOT for the work we are doing, and to make the work more inclusive and visible to the team and the wider group,
we should post a status update on the Delivery Group Standup channel (#g_delivery_standups) at least two times a week (more updates are welcome). The status updates should provide what we completed, what we plan to do today, and what we will do next, and items not work-related and part of everyday life. In the Status Update, links to Progress Thread comments are highly recommended so that we can provide more context and use the Issue as SSOT for discussions.
We use Geekbot to automate the standup reminder. An example of a status update is:
|
|
The Delivery group generally has working epics assigned to a [DRI] who is responsible for making sure work is broken down into issues, and appropriate issues are moved onto the [Build board] to keep the project on track. However, anyone is welcome to pick up any tasks from the [Build board] regardless of which project it belongs to.
The Delivery group respects the Company principle of everything starting with a merge request.
Besides, we try to apply some best practices when doing Merge Requests:
As part of the project, we might decide to organize project demos. The decision on creating a demo depends on the expected longevity of the project, but also on the complexity of it.
The purpose of the demo is to ensure that everyone who participates in the project has a way of sharing their findings and challenges they might have encountered outside of the regular async workflow. The demos do not have presentations attached to them, and they require no prior preparation. The demoer shouldn’t feel like they have to excuse themselves for being unprepared, and expect that their explanation without faults. In fact, if what is being demoed is showing off no weaknesses, we might have not cut scope in time.
It is encouraged to show and discuss:
Every Delivery Group member is responsible for sharing skills either through creating a training session for the rest of the group or through paired work. See the page on team training for details.
The Delivery team officially came into existence on 2018-10-23. This was the culmination of a larger alignment that was happening throughout that year, exposed by the need to streamline releases for self-managed users and creating a better experience for GitLab.com users.
All throughout GitLab’s existence, Release Management had been a monthly rotating role served by developers. The idea behind it was to keep developers close to the whole lifecycle of the software they create, and ensure that they automate their work. This worked well until the number of application changes, and developer tasks grew too large for anyone to handle as a secondary task. The event that indicated the need for a change was a near miss event near the end of 2017, when the first Release Candidate was deployed to GitLab.com just 2 days before the 22nd. That whole month was riddled with challenges, from release managers struggling to deliver their day to day development tasks and RM tasks, to multiple unsuccessful deployments to GitLab.com. Most importantly, this was a first indication that the company was growing and that the processes that worked previously, might need to change to accommodate the larger growth that was planned.
After some internal discussions, we entered 2018 with an attempt to work on process improvements, rather than changing everything in one go. We went from a monthly rotation to two month release manager rotation, started noting down spent time. Over the next several months we’d seen general stabilization of the process but it became apparent that spending 4 engineers time in Release Manager rotation was not getting us anywhere closer to improving the deployment process for GitLab.com, and with each developer we hired the task list grew bigger.
The initial discussion on what is in front of us to achieve Continuous Delivery on GitLab.com exposed a clear need for a team focused on this specific task.
With the team created, we set out to work on the release we designed, change the way we deploy to GitLab.com, merge GitLab Rails codebases and many more other tasks.
After a successful team onsite (aka Fast boot) where we executed on our tasks while being in the same room together for the first time, we announced the first step towards Continous Delivery on GitLab.com. This was a very large change that changed the deployment frequency from deploying from the default branch once per month (for the total of 4-6 deploys to include bug fixes), to taking commits from the default branch once per week.
The team focus then shifted to getting deployment time measured in hours, and migration of GitLab.com to Kubernetes.
Prior to 2020, the team impact overview was created in Slack, and in the years that followed the overview was logged in issues:
Delivery Sisense PIs [triage ops]: https://gitlab.com/gitlab-com/gl-infra/triage-ops [DRI]: /handbook/people-group/directly-responsible-individuals/ [Build board]: https://gitlab.com/gitlab-com/gl-infra/delivery/-/boards/1918862
ce9e1faf)
